lab7-2 Wireshark-HTTP
Lab7-2 HTTP
1 Objective
通过实验了解HTTP(超文本传输协议)的主要信息。HTTP是Web的主要协议。
2 Steps
Step 1: Capture a Trace
实验手册中提供了本实验的抓包结果,可以直接点击链接下载。
Step 2: Inspect the Trace
我们可以在应用显示过滤器中输入http来只查看http请求或响应包。

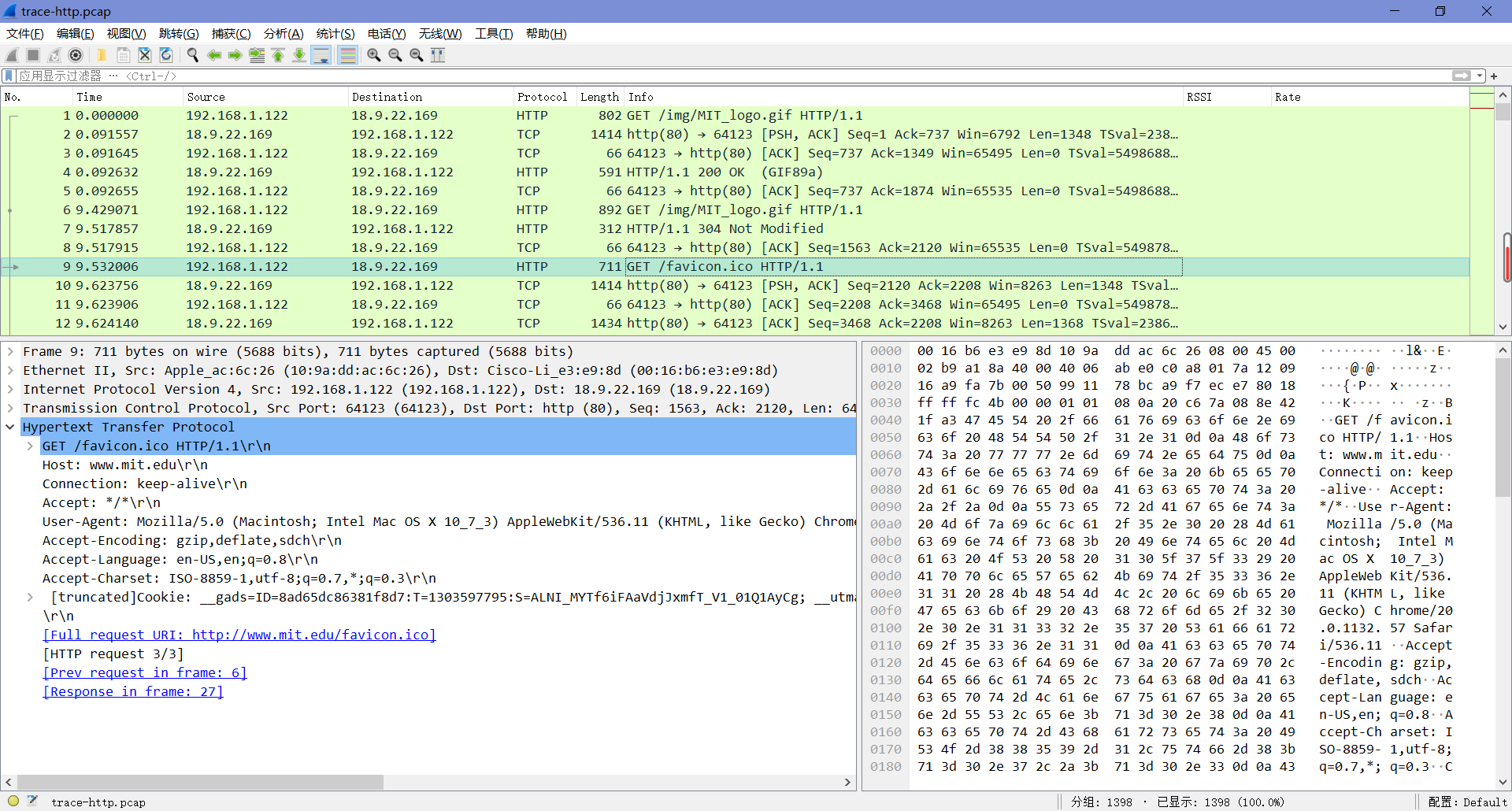
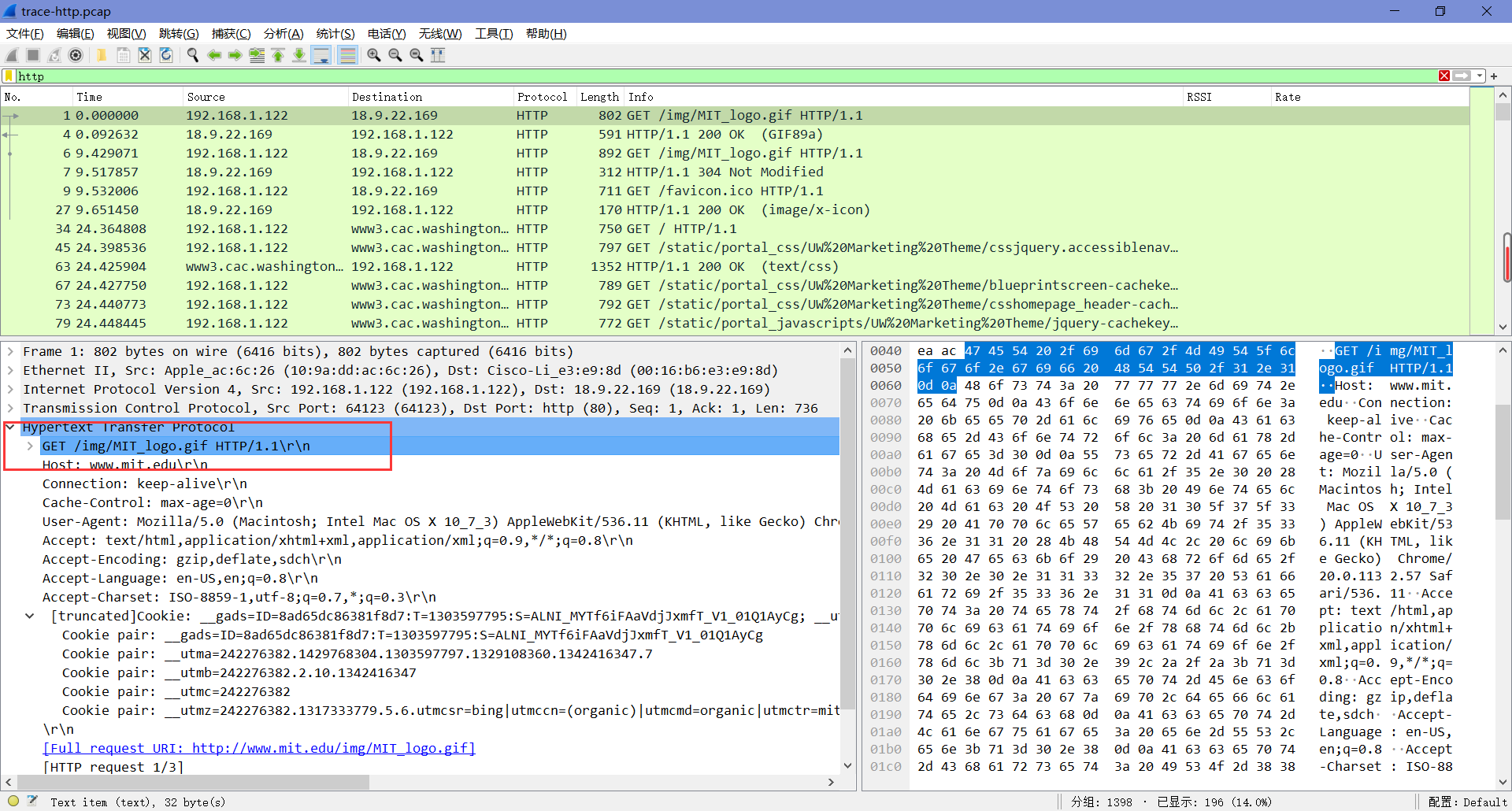
选择第一个HTTP请求包并展开它的HTTP块,查看其详细信息:
- “Host”是一个必须有的头部,它标识了服务器的名称(和端口)。
- “User-Agent”描述了浏览器的类型及其功能。
- “Accept”、”Accept-Encoding”、”Accept-Charset”和”Accept-Language”对应了响应中接受的格式的描述。
- “Cookie”是浏览器为网站保存的cookie的名称和值。
- “Cache-Control”描述了如何缓存响应。
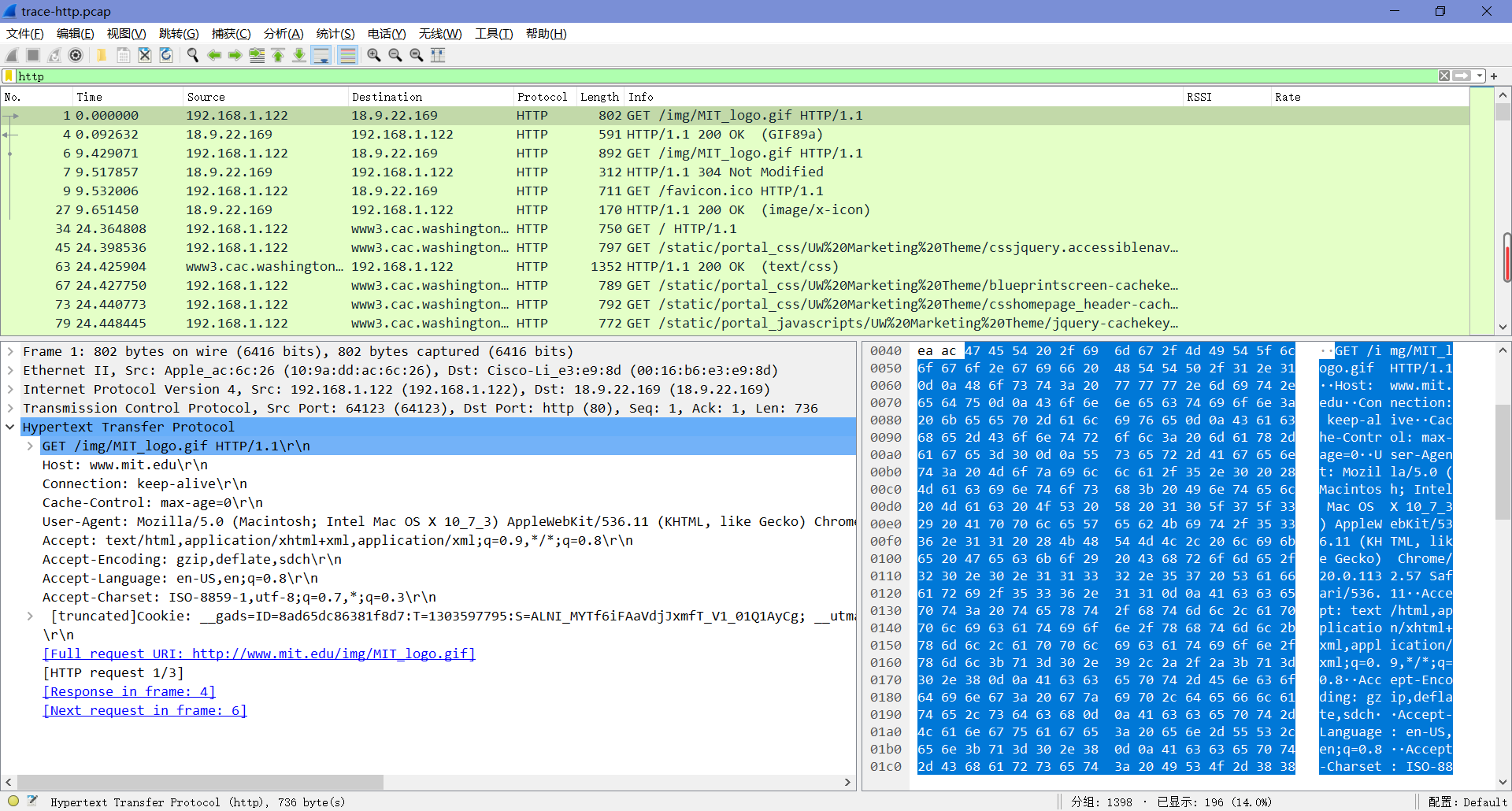
选择与第一个HTTP请求包对应的HTTP响应包并展开它的HTTP块,查看其详细信息:
- “Server”描述了服务器的类型及其功能。
- “Date”和”Last-Modified”描述了响应的时间和内容最后更改的时间。
- “Cache-Control”、”Expires”和”Etag”是关于如何缓存响应的信息。
What is the format of a header line? Give a simple description that fits the headers you see.
对HTTP请求来说,header line由请求方法字段、URL字段和HTTP协议版本字段3个字段组成,它们用空格分隔。
对HTTP响应来说,header line由服务器HTTP协议版本、服务器发回的响应状态代码和状态代码的文本描述3个字段组成,它们用空格分隔。
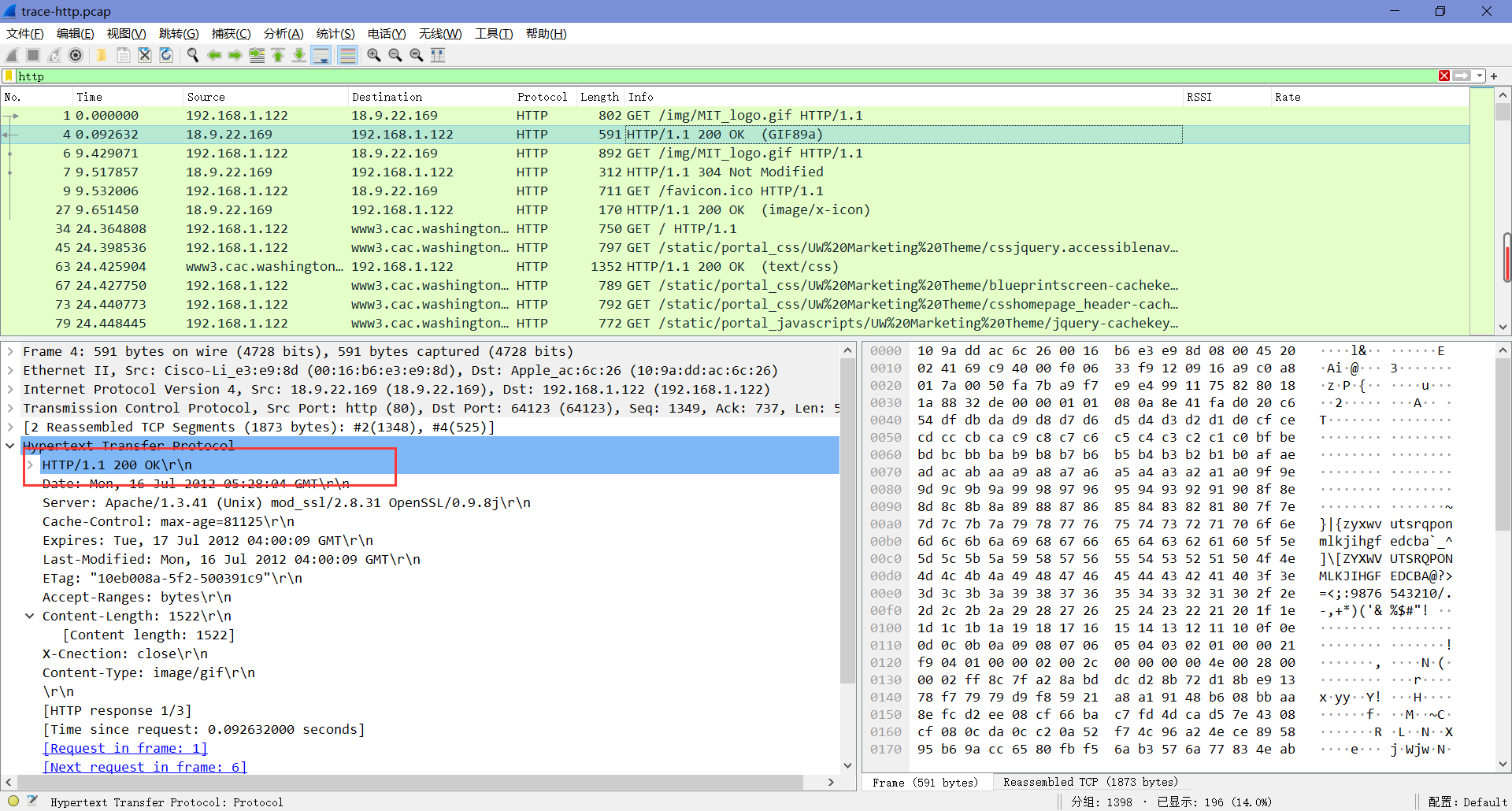
What headers are used to indicate the kind and length of content that is returned in a response?
如图,为”Content-Type”和”Content-Length”。
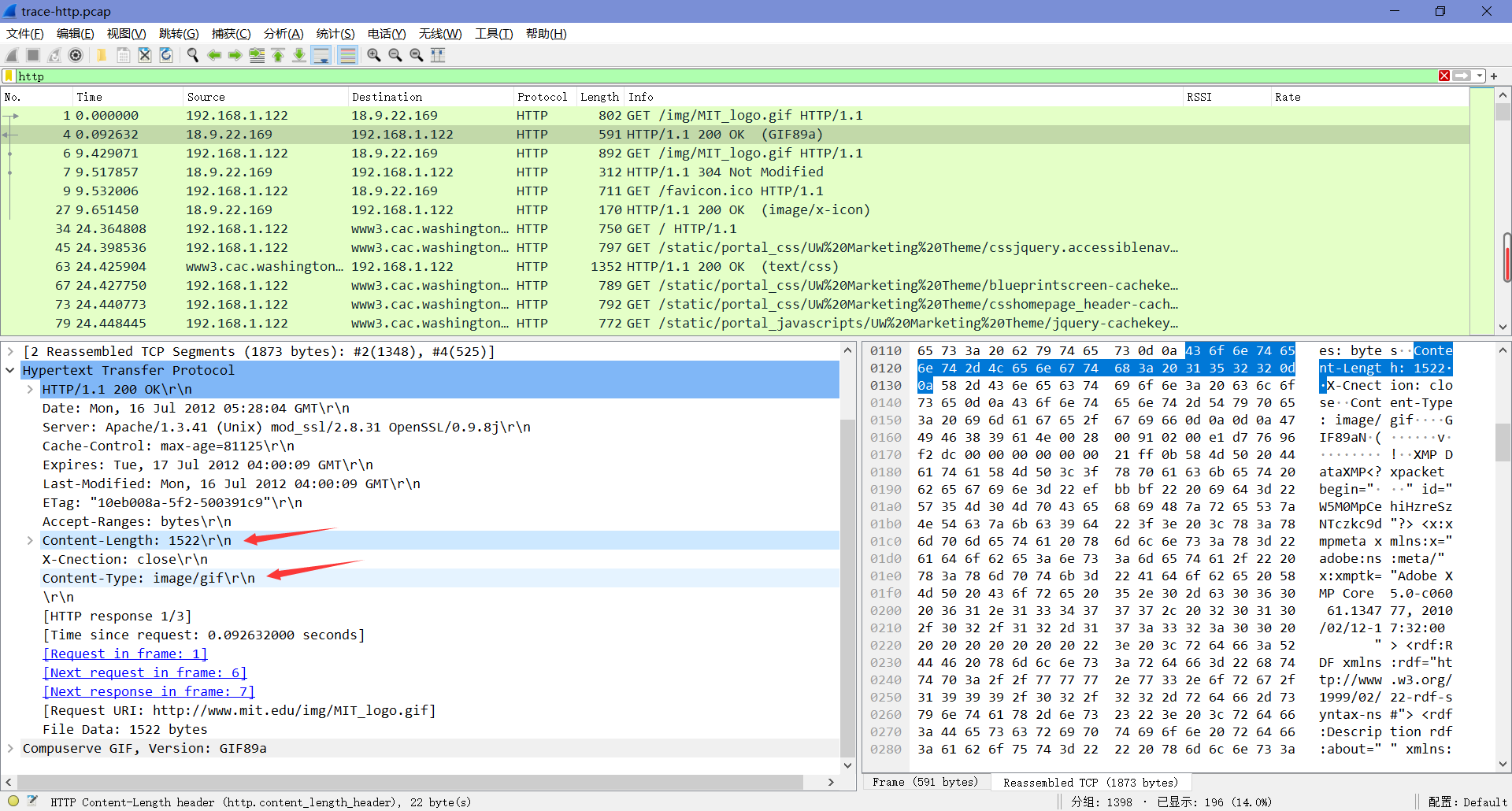
Step 3: Content Caching
通过查看抓包结果我们可以发现,抓包结果中的第二个GET包应该是第一个URL的重新获取。这为我们提供了一个查看缓存操作的机会,因为很有可能图像或文档没有更改,因此不需要再次下载,HTTP缓存机制应该能够识别这种机会。现在我们来看看它们是如何工作的。
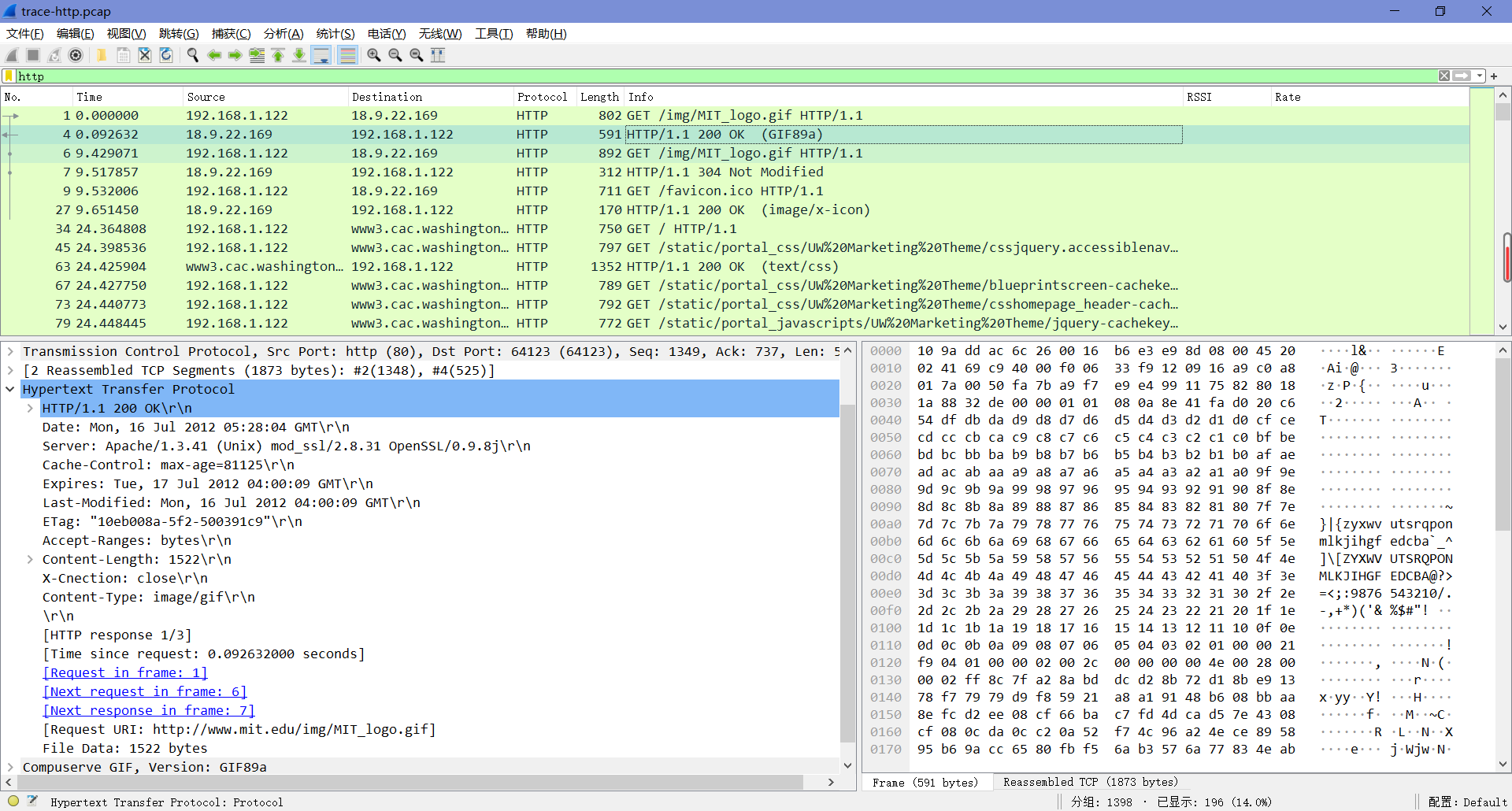
选择第一个GET的重新获取的GET,并展开它的HTTP块。
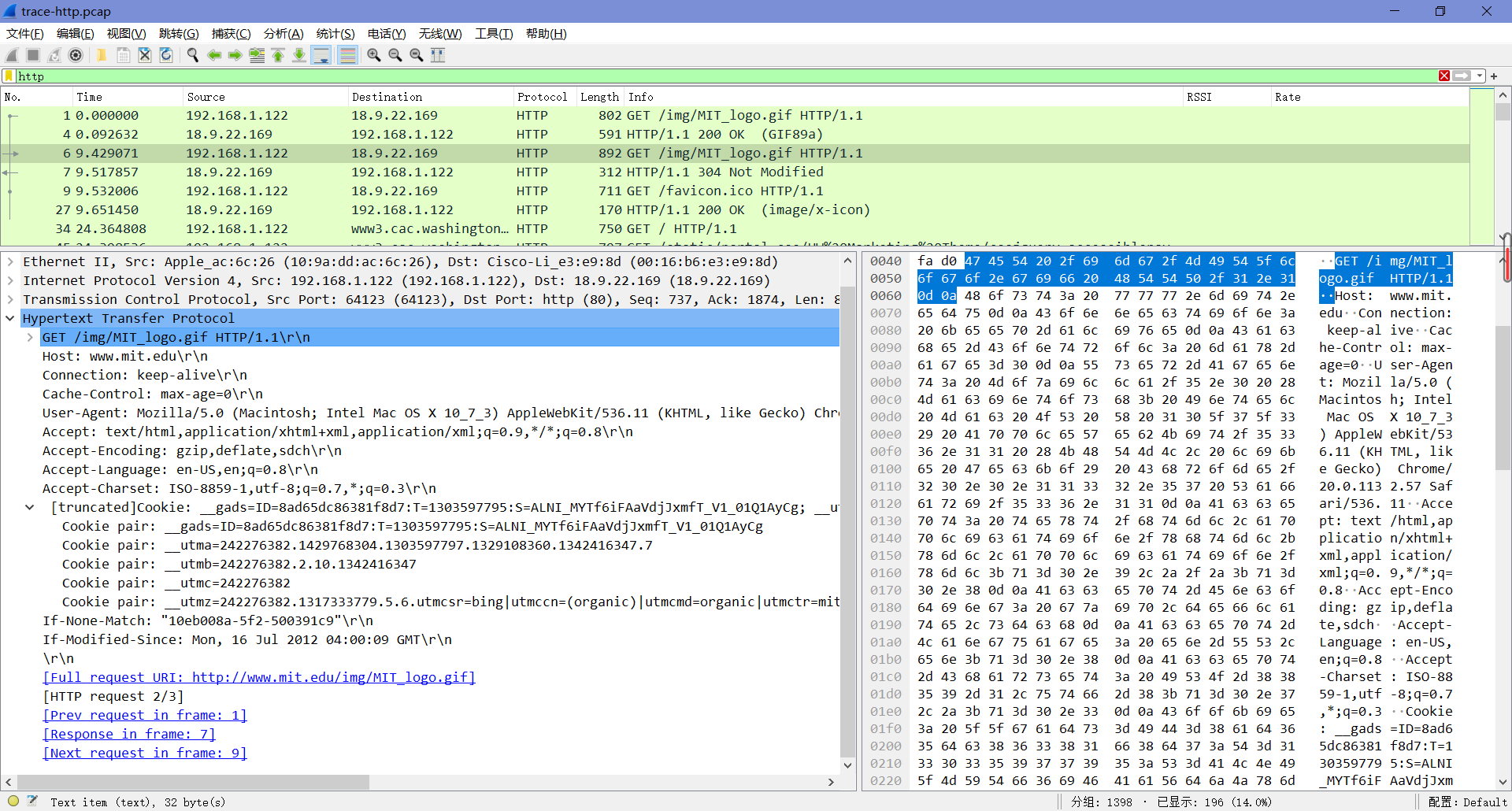
现在找到让服务器判断是否需要发送新内容的报头。只有当内容自浏览器上次下载后发生了更改时,服务器才需要发送新内容。为了解决这个问题,浏览器包含一个时间戳,从上一次下载中获取它缓存的内容。这个头没有出现在第一个GET包中,因为我们清除了浏览器缓存,所以浏览器没有以前下载的可以使用的内容。在大多数其他方面,这个请求将与第一次请求相同。
最后,选择要重新获取的响应包,并查看它的HTTP块。
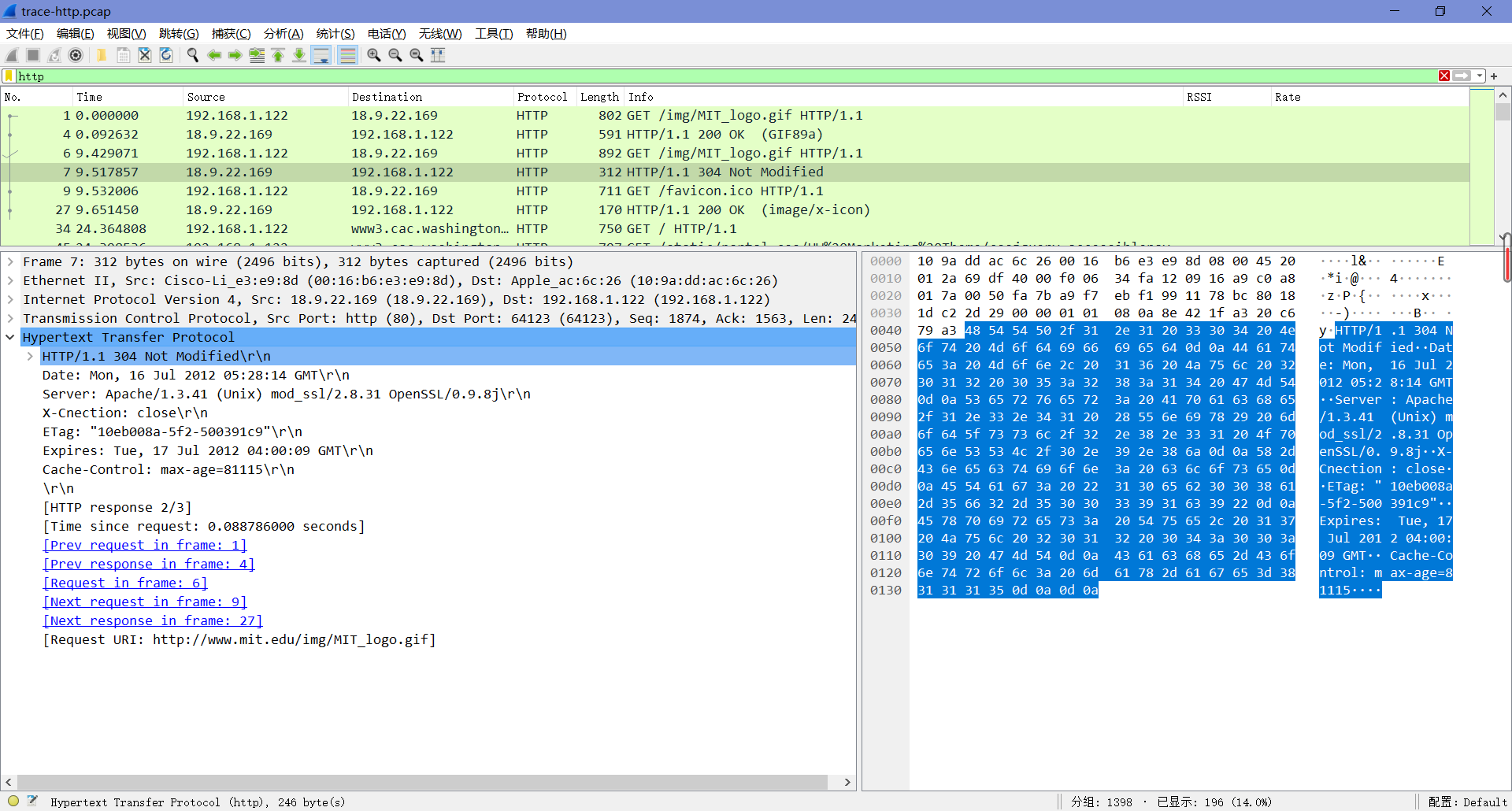
假设缓存按预期工作,此响应将不包含内容。相反,响应的状态代码将是“304 Not Modified”。这将告诉浏览器,内容与以前的副本没有变化,然后可以显示缓存的内容。
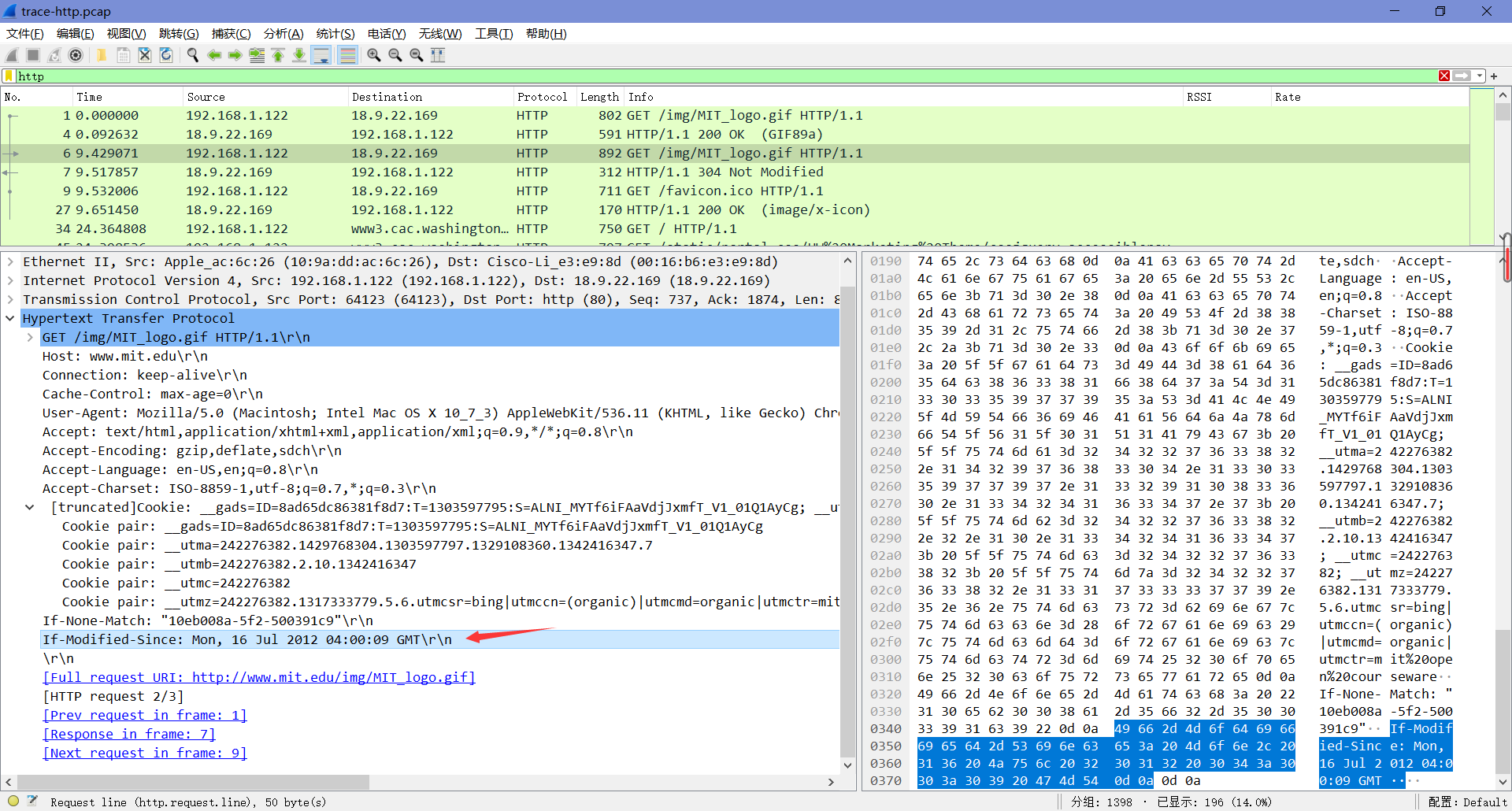
What is the name of the header the browser sends to let the server work out whether to send fresh content?
这个报头叫做”If - Modified - Since”,也就是说,它要求服务器发送自给定时间以来是否被修改过的内容(如下图)。
Where exactly does the timestamp value carried by the header come from?
时间戳值来自最近下载的内容的“Last-Modified”报头。
Step 4: Complex Pages
现在我们将检查第四个HTTP请求(实验手册中说第三个,但第三个是”/favicon.ico”的GET,这是浏览器请求站点的图标作为浏览器显示的一部分)。这种获取方法适用于更复杂的web页面,其中可能包含嵌入式资源。因此,浏览器将下载初始HTML加上渲染页面所需的所有嵌入式资源,再加上执行页面脚本期间请求的其他资源。正如我们将看到的,单个页面可以涉及多个GET。
我们可以通过打开一个”统计-HTTP”中的负载分配面板来总结本页的GET,查看这个面板将显示本机向哪些服务器发出了多少请求。
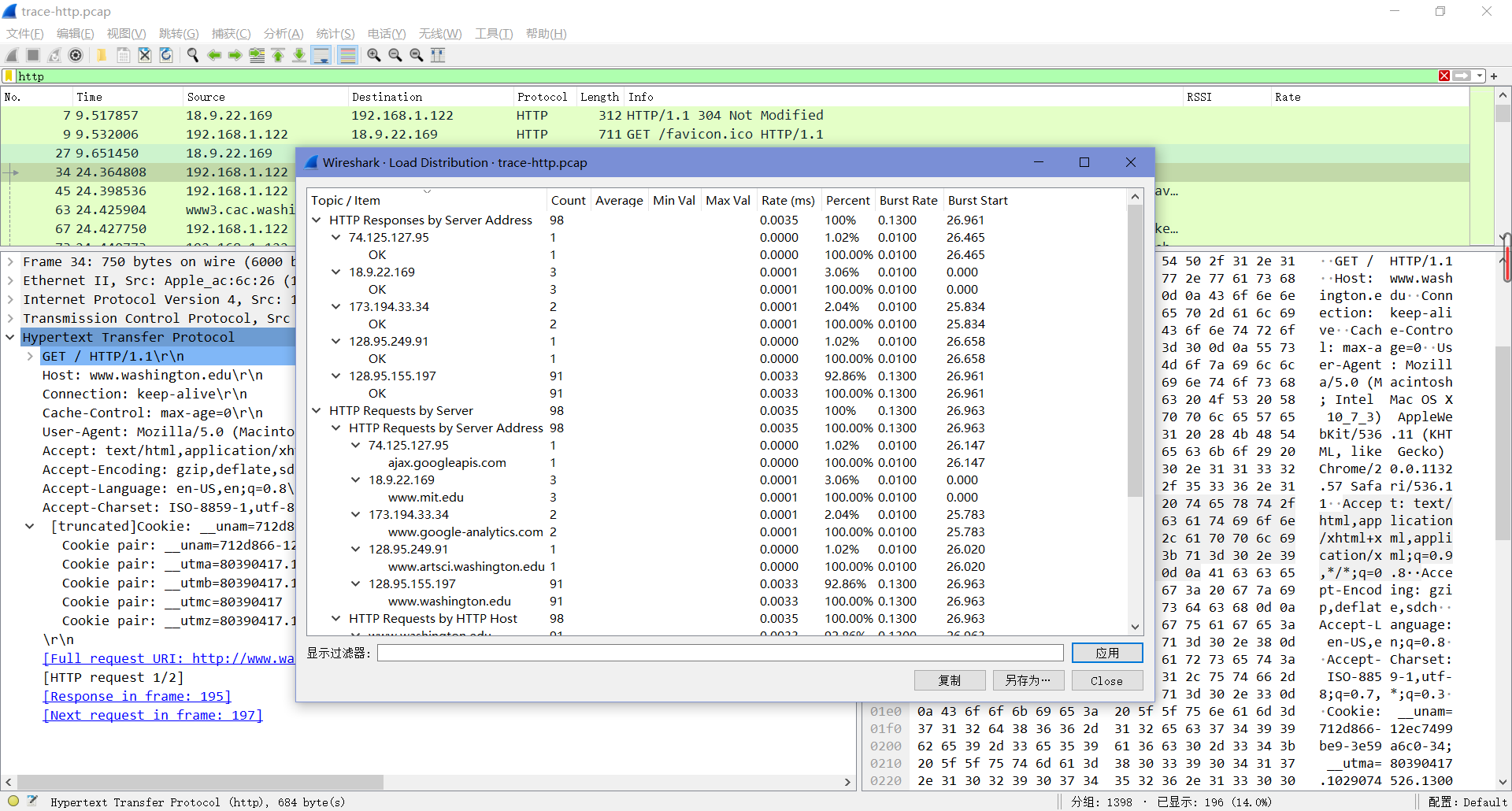
我们也可以通过打开一个”统计-HTTP”中的分组计数器面板来总结本页的GET,这个面板显示了请求和响应的类型。

可以使用一个网站如谷歌的PageSpeed或ebpagetest.org来更详细地了解整个页面加载过程。这些网站将测试已选择的URL,并生成页面加载活动的报告,显示在什么时间获取了什么请求,并给出减少整体页面加载时间的提示。
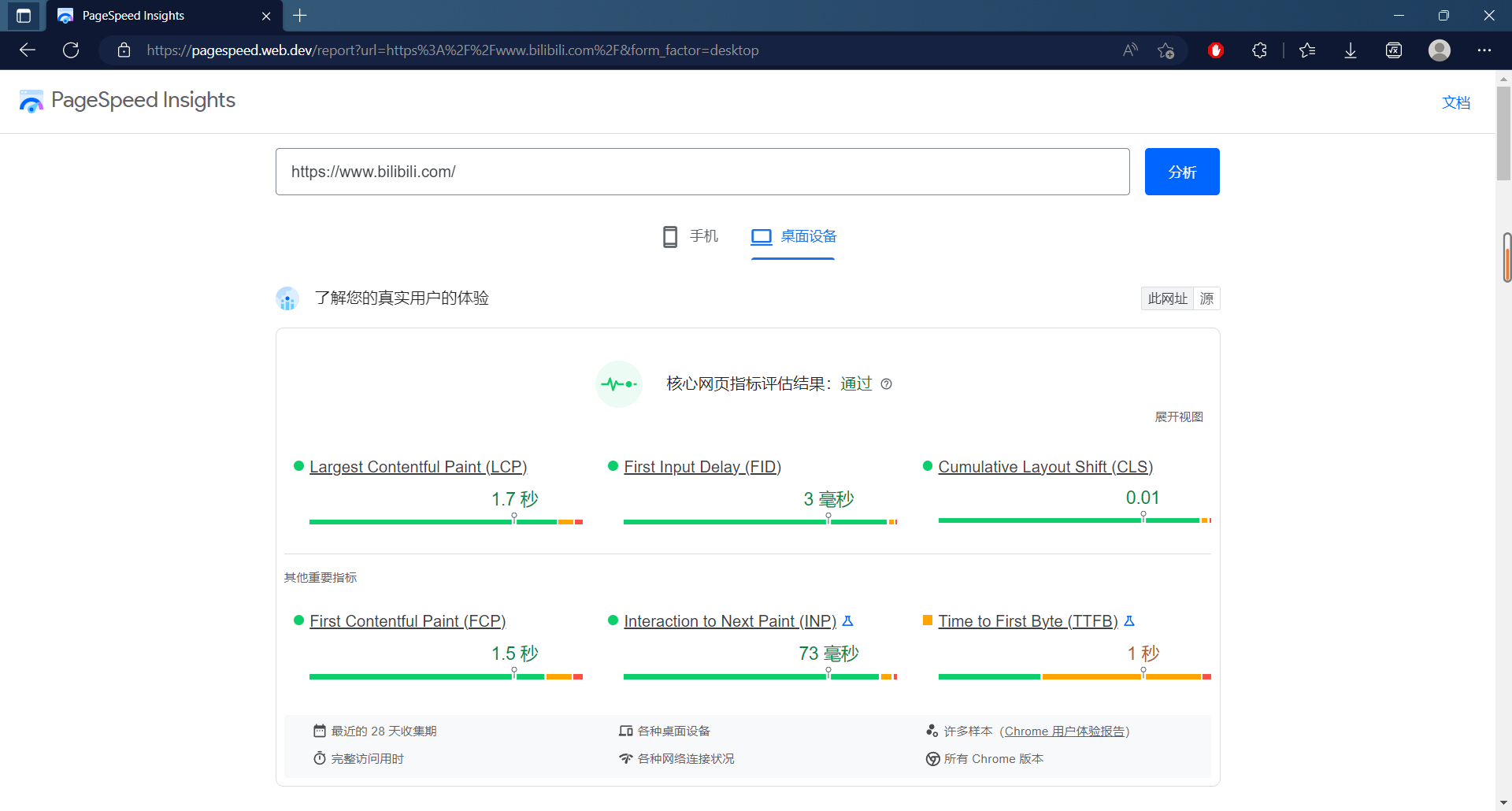
得到的瀑布图如下。
